一个对比AI影像和传统影像的论文,介绍各自的特征
深度学习简单直接自动化,大力出奇迹;影像组学步步为营靠人工,识珠靠慧眼。两种方法本质上都依赖大数据,都可以划分为图像预处理、特征筛选和特征建模三个阶段。
传统影像组学
方法上,影像组学提取传统的图像特征,包括形状、灰度、纹理等,采用传统统计(模式识别)模型来分类和预测,如支持向量机、随机森林、XGBoost等;
Overview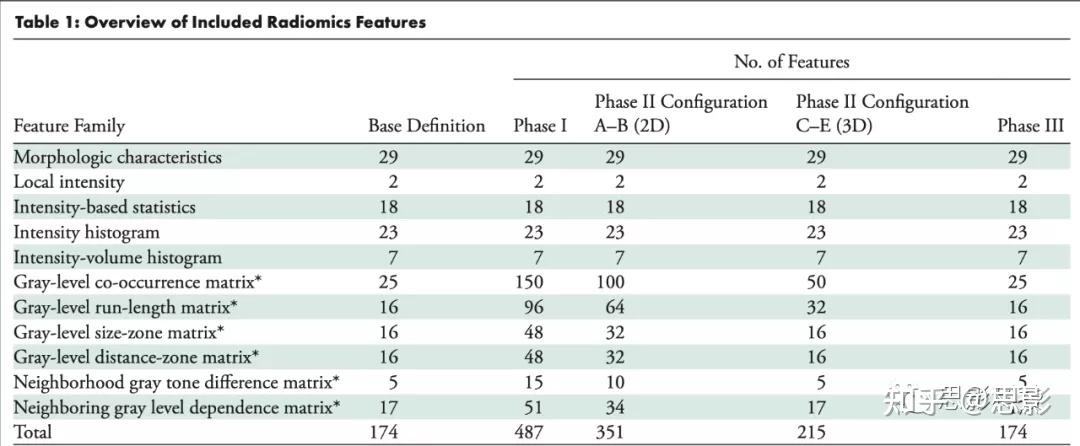
AI影像组学
深度学习人工智能模型
放射组学基于人工智能治疗预后
DL方法基于深度神经网络进行模式识别,模式识别通常包括一系列可训练的非线性操作,称为层,每个层将输入数据转换为便于模式识别的表示。随着越来越多的层对输入数据应用转换,这些数据越来越多地抽象为深层特征表示。由此产生的深层特征最终可以由网络的最后一层转化为所需的输出,例如治疗结果的可能性或肿瘤的分子亚型。深度学习是一个广泛的、技术性的、动态发展的领域。我们简要介绍了基于预测的AI影像学中最常见的主题,并对深层神经网络的类型、常用框架、解决数据局限性的方法进行了更详细的补充讨论。所有这些问题在别的研究中都有综述。
VGG实现特征提取
常用代码&注解
查看模型结构
1 | # 查看模型整体结构 |
运行后可知:
vgg19整体结构分为三大部分:
- ‘features’:上面输出的VGG19模型结构中的第一个Sequential,包含(0)-(36)层;
- ‘avgpool’:VGG19模型结构的第二个部分AdaptiveAvgPool2d;
- ‘classifier’:VGG19模型结构的最后一个部分Sequential,包含(0)-(6)层。注意其中Linear特征维度是1000,其余均为4096.
修改模型结构
可以获取各个部分,切割层数
1
2
3
4
5
6
7
8
9
10
11# 获取vgg19模型的第一个Sequential, 也就是features部分.
features = torch.nn.Sequential(*list(vgg_model.children())[0])
print('features of vgg19: ', features)
# 获取vgg19模型的最后一个Sequential, 也就是classifier部分.
classifier = torch.nn.Sequential(*list(vgg_model.children())[-1])
print('classifier of vgg19: ', classifier)
# 在获取到最后一个classifier部分的基础上, 再切割模型, 去掉最后一层.
new_classifier = torch.nn.Sequential(*list(vgg_model.children())[-1][:6])
print('new_classifier: ', new_classifier)用new_classifier替换vgg19原始模型中的分类器( classifier )部分,就得到了输出维度是4096的VGG19模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import torch
import torchvision.models as models
from torchvision import transforms
from PIL import Image
# 获取vgg19原始模型, 输出图像维度是1000.
vgg_model_1000 = models.vgg19(pretrained=True)
# 下面三行代码功能是:得到修改后的vgg19模型.
# 具体实现是: 去掉vgg19原始模型的第三部分classifier的最后一个全连接层,
# 用新的分类器替换原始vgg19的分类器,使输出维度是4096.
vgg_model_4096 = models.vgg19(pretrained=True)
new_classifier = torch.nn.Sequential(*list(vgg_model_4096.children())[-1][:6])
vgg_model_4096.classifier = new_classifier
# 获取和处理图像
image_dir = '/mnt/image_test.jpg'
im = Image.open(image_dir)
trans = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
im = trans(im)
im.unsqueeze_(dim=0)
# 使用vgg19得到图像特征.
# 原始vgg19模型
image_feature_1000 = vgg_model_1000(im).data[0]
print('dim of vgg_model_1000: ', image_feature_1000.shape)
# 修改后的vgg19模型
image_feature_4096 = vgg_model_4096(im).data[0]
print('dim of vgg_model_4096: ', image_feature_4096.shape)简化版本:只需要原始vgg19模型的第一个部分features部分的输出结果.但是只适用于联网加载的vgg19模型(即设置了pretrained=True的模型),不适用于使用了本地vgg19模型的vgg_model
1
2
3
4
5
6
7# 获取vgg19原始模型的features部分的前34个结构, 得到新的vgg_model模型.
vgg_model = models.vgg19(pretrained=True).features[:34]
# 但是下面的代码只能得到classifier部分的前40个,
# 而不能得到包含features及avgpool及classifier的一共前40个结构.
# 所以这个方法不能实现输出4096维度图像特征的目标.
# vgg_model = models.vgg19(pretrained=True).classifier[:40]一些小tips
- 修改特征类型
1
2把`VGG16_Weights.IMAGENET1K_FEATURES`
改成`VGG16_Weights.IMAGENET1K_V1`
- 修改特征类型
用于预测的卷积神经网络
在放射学中,大多数基于DL的生物标记物应用都使用卷积神经网络从成像数据得出预测(图3a)。卷积神经网络是神经网络的一种特殊形式,用于学习图像的空间特征,并且由于它们在诊断任务中的表现,受到了广泛的关注。在几项引人注目的研究中,基于CNN的模型在诊断胸片和CT以及数字乳房X光摄影方面甚至超过了专业的人类专家。正如CNN已被证明能够学习指示恶性肿瘤的图像特征一样,越来越多的研究表明,它们可以根据与预后、风险和分子特征相关的肿瘤性质的细微差异对患者进行分型(图3a)。当使用患者结果数据进行训练时,CNN的卷积层可以学会识别反映预后的新成像表型。CNN可以应用于2D或3D输入,并且可以使用多个输入,以便从图像类型的组合中学习,例如多参数或动态MRI扫描。大量的CNN结构可以选择来用于基于AI的生物标记物研究(补充表2)。补充框2中进一步详细讨论了它们的原理和优势。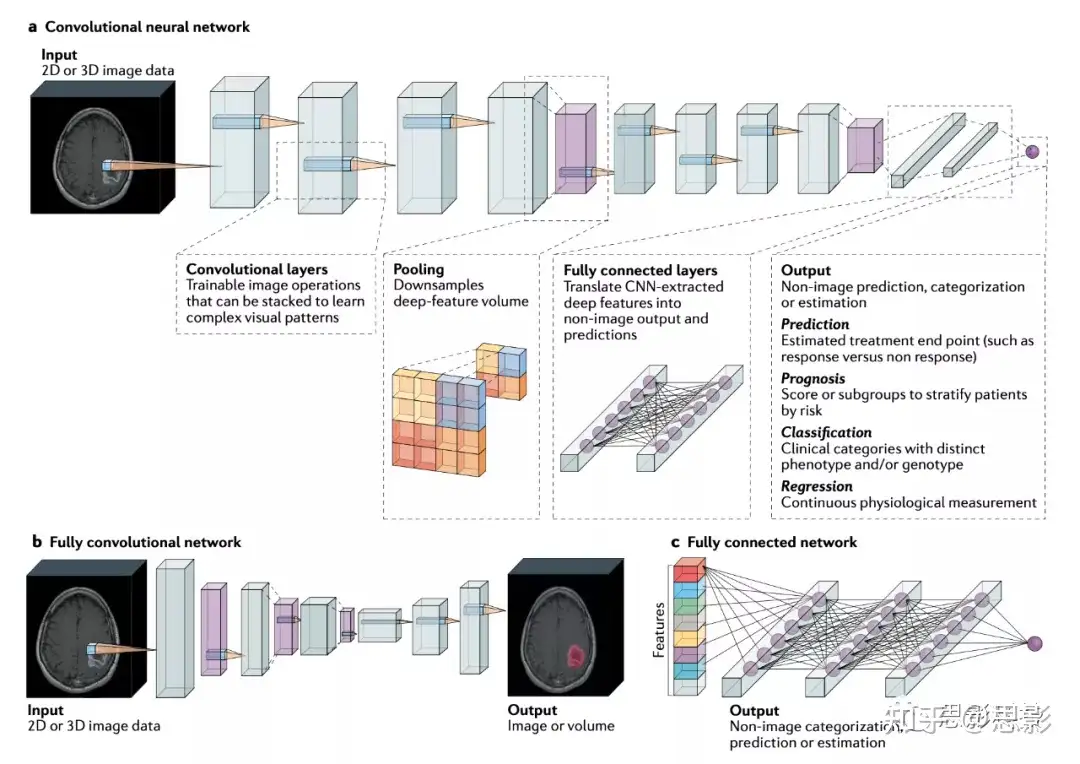
用于预测的卷积神经网络(CNN)模型示例。输入图像或体积通过CNN层,CNN层执行操作并将其转换为目标输出向量。卷积层是将成像数据转换为深度特征表示的一组操作。每个过滤器通过图像,并与非线性激活函数配对,以强调特定任务感兴趣的视觉模式。随着更多的卷积层层叠,CNN可以在图像中学习到更复杂的视觉模式。在整个CNN分类器中,深度特征通过池化操作定期聚合。经过卷积层和池化层处理后,深度特征表示最终被展平为向量。接下来,完全连接的层将这些CNN衍生的图像特征转换为对应于目标输出的向量。这些模型可用于预测治疗反应、预测、肿瘤亚型和生物标志物的分类以及生理值的预测。
全卷积神经网络是一种CNN类型,只包含产生图像输出的卷积层,如肿瘤位置图。
完全连接的网络可以根据非图像数据进行训练,如影像组学特征和临床变量。
当对模型进行结果预测训练时,对大量数据的需求可能会存在局限性,在这种情况下,可行的患者数据可能比诊断研究更加有限。幸运的是,尽管训练数据很少,但有几种方法可以利用神经网络的优势。例如,迁移学习,其中针对一个模式识别任务训练的模型被重新调整用途以执行新任务,经常用于在训练数据大幅减少的情况下实现强大的CNN性能其他方法可用于处理有限或有缺陷的训练数据。
一些论文
一个特征提取网络的介绍
Deep Feature——用深度网络来提取特征
Pure DL直接使用Autoencoder来提取特征,然后直接进行分类。
采用LIDC中已经标记(分割)好的肺结节病灶区域作为ROI,对ROI的最小包围矩形区域进行尺寸归一化,然后输入一个5层Autoencoder网络进行特征编码,对Autoencoder网络进行训练。之后,使用训练优化完成后的5层网络中的第4层网络输出,共200个特征向量,输入一个二值分类树,区分肺结节良恶性。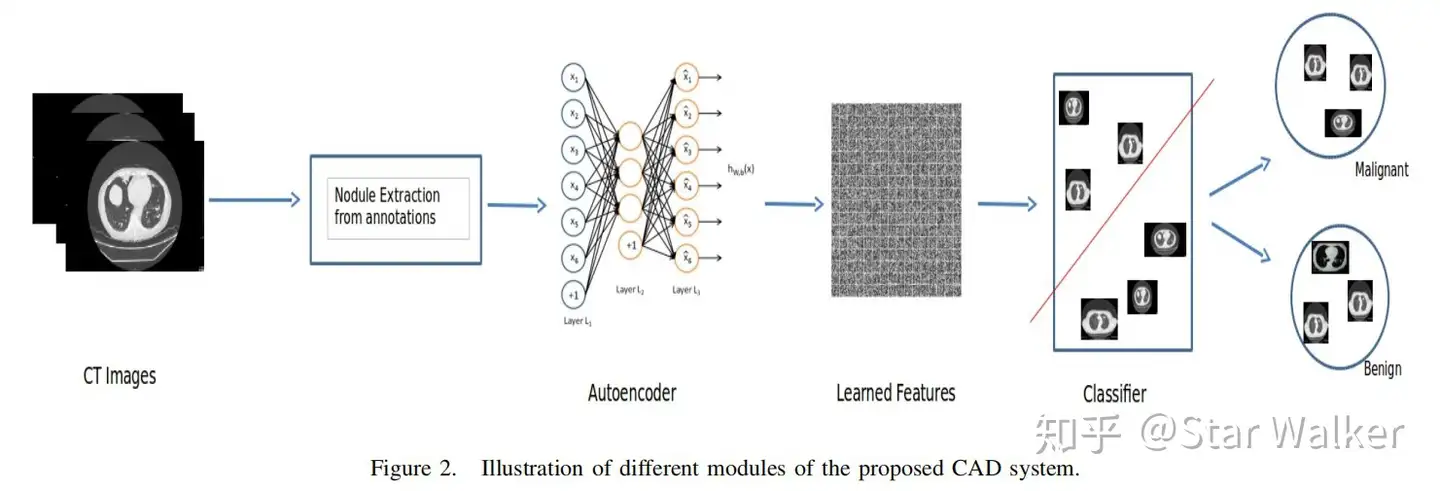
但是这种方法准确度有待考量。
!DL+Tr可以预测生存周期
在传统的影像组学三大件(形状、灰度、纹理)之上,又添加了来自于深度学习网络的深度特征(Deep Feature)。所使用的深度学习网络包含5个卷积层和3个全连接层。倒数第二个(full7)和倒数第三个(full6)全连接层的输出,共8192个特征,与其他影像组学特征一起输入预测模型,来预测多形性成胶质细胞瘤患者的生存周期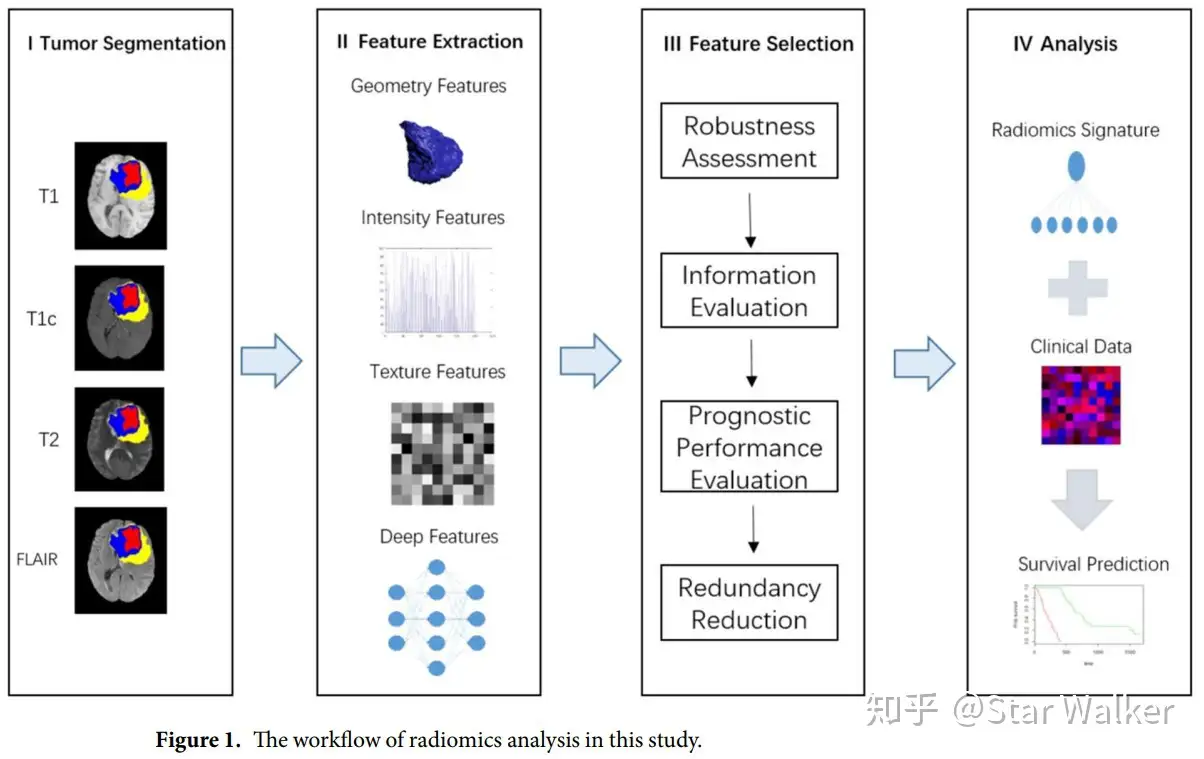
!DRL
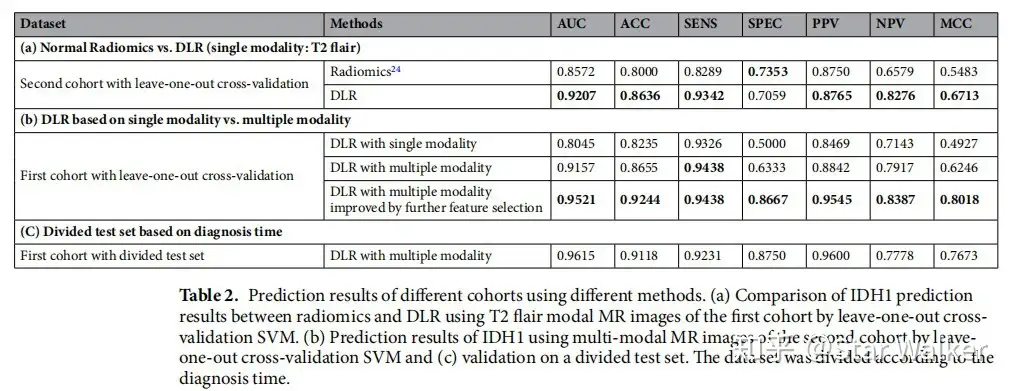
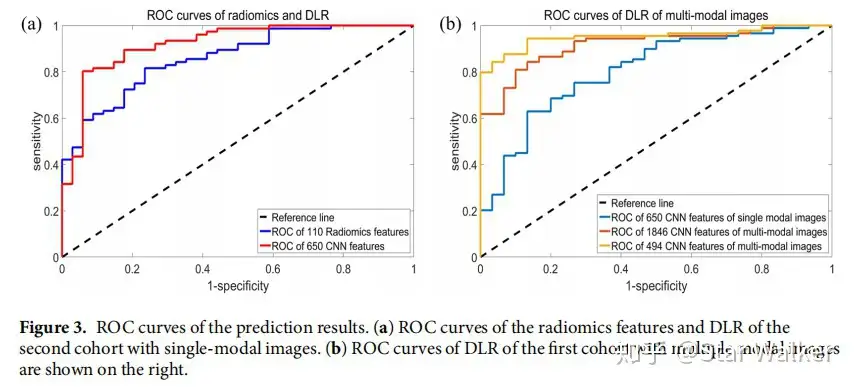
直接采用CNN网络的输出作为特征,连接传统的分类器(预测器)进行分类和预测。作者在MR多模态影像上,测试和验证了DLR预测低级别胶质瘤突变分级的准确性。下方依次给出的是整体流程图,以及将DLR与传统影像组学方法的特异性、敏感性等对比、ROC对比。从对比可以看出,DLR方法在各项指标中几乎全面胜出。并且,对比中发现,采用多模态影像,并且对特征进行进一步筛选,得到的各项指标是最高的。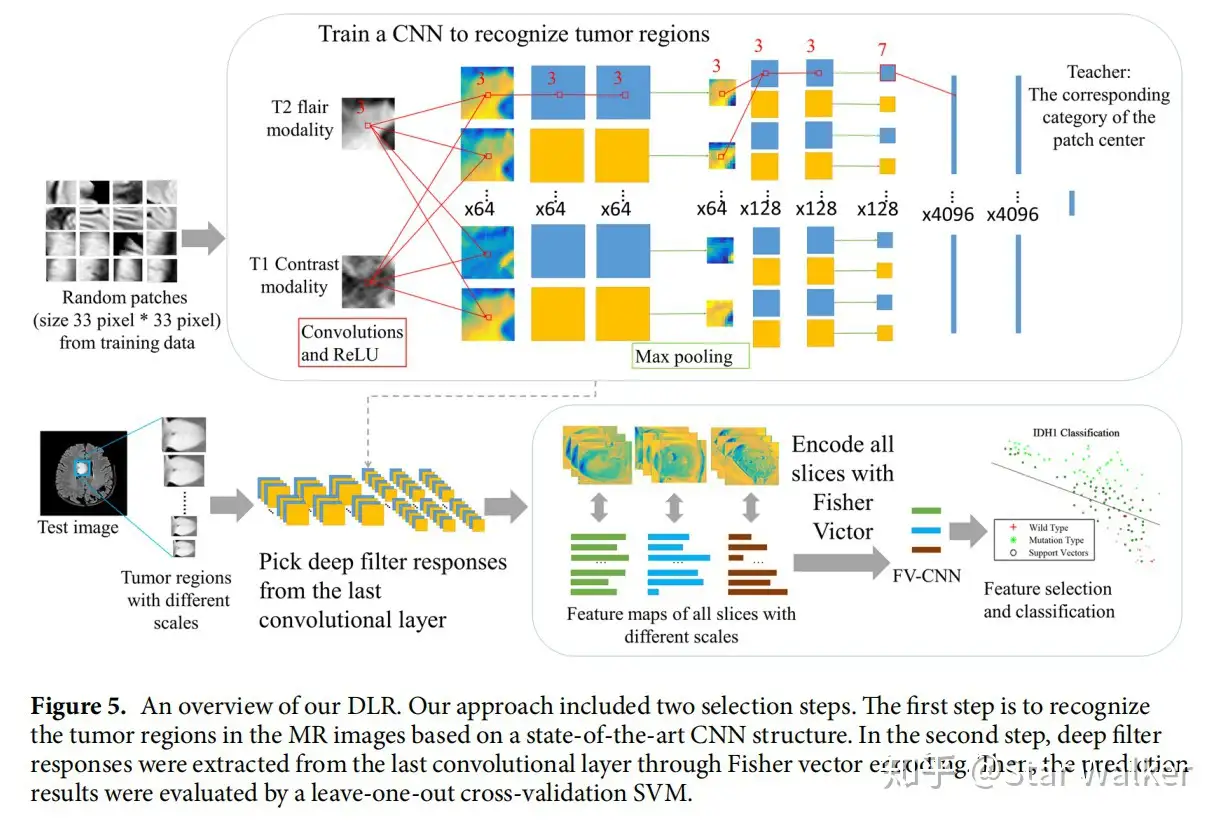
VGG-16 Architecture for MRI Brain Tumor Image Classification
- 初始阶段是对样本图像进行预处理,然后使用池化层进行过滤,使用卷积层进行特征提取,最后使用架构模型的 FC 层进行分类。来自分子脑肿瘤数据库(REpository of Molecular BRAin Neoplasia DaTa,REMBRANDT)的核磁共振图像使用了预先训练好的模型架构,如视觉几何组(VGG)VGG-19、VGG-16、Inception-V3、Inception-V2、残差网络(ResNet)ResNet-18 和 ResNet-50。
- The use of DL and TL methods to diagnose and classify brain tumors using MRI brain images has been proved to be a promising methodology.contains many CNN designs, including ResNet,Inception, and VGG networks.
- Figure 2 illustrates the CNN model’s architecture for brain tumor categorization.
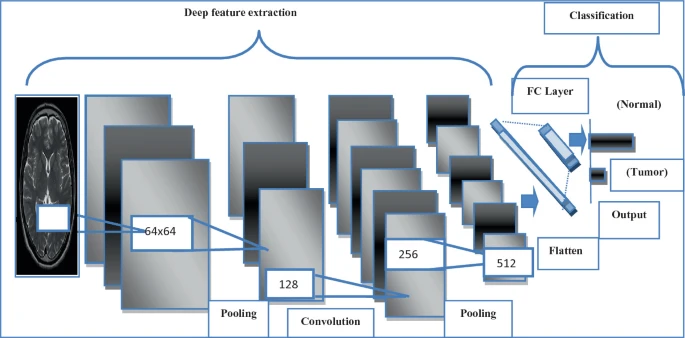
- 从大脑图像中提取的深度特征被输入到设计的具有预训练特征的 CNN 模型中。**(GoogleNet)Inception-v2、Inception-V3、ResNet-18 [14]、ResNet-50 VGG-19 和 VGG-16 是本研究中使用的六个预训练 CNN 模型**。
- 最初,VGG-16 和 VGG-19 架构模型都将核磁共振成像脑图像作为输入。深度特征从网络的卷积层和最大池化层提取。随着深度的增加,分类误差也随之减少,直到达到 19 层时,分类误差才趋于饱和。研究人员还验证了深度在图形表示法中的重要性。
- CNN performs better in larger datasets than the smaller ones. When it is not possible to produce a big training dataset, TL can be utilized.
- Conclusion: 具有 16 个网络层的 VGG-16 架构在将 MR 脑图像分类为肿瘤或正常图像方面提供了更高的准确度、精确度、F1 分数和召回率。
二者比较
深度学习并没有完全取代影像组学。主要的原因还是数据集规模的限制。
深度学习能够大幅提高分类或预测模型的准确性,但这是有代价的。相比影像组学,深度学习方法需要更多的训练数据。但影像组学所研究的问题往往是某种肿瘤的分期或分型,或者是预后生存率,此类问题的训练数据(Grand Truth数据)收集成本是非常高昂的,一般需要病理或术后随访来进行验证。因此,训练数据集的规模通常数量级在几百,与深度学习常见的数千、上万级数据集相差很远。
可以采用深度学习中普遍采用的数据增强手段(Data Augmented)了。这在一定程度上弥补了数据缺口。而数据增强在传统的影像组学中是无法采用的。